The nice thing about working at an AI company is that sometimes we get to see cool tech-related stuff that is only tangentially related to my day-to-day. It’s even better when this turns out to be stuff that legitimises my degree in English Literature – not exactly famous for being the most vocational of subjects to study.
This is how I felt the other day when John, the brains behind the technology at Discover AI, posted this piece, catchily titled, Measuring the similarity of books using TF-IDF, Doc2vec and TensorFlow. This is an exploration of what happens when John used “machine learning to map books onto a two-dimensional plane so we can explore a library and potentially find other titles we may be interested in reading”. You should read his article if you’re interested in finding out how he did this – there’s even a link to the code behind it, if you’re interested in trying it out yourself. You should read his article anyway because the magic of a hyperlinked internet means we all have multiple attention spans and can jump between several things at once.
However, you should stay here, (or come back – read in whatever order you like) if you want to see what happens when a nostalgic ex-English student whose job involves qualitatively analysing AI sourced data takes a look at the results.
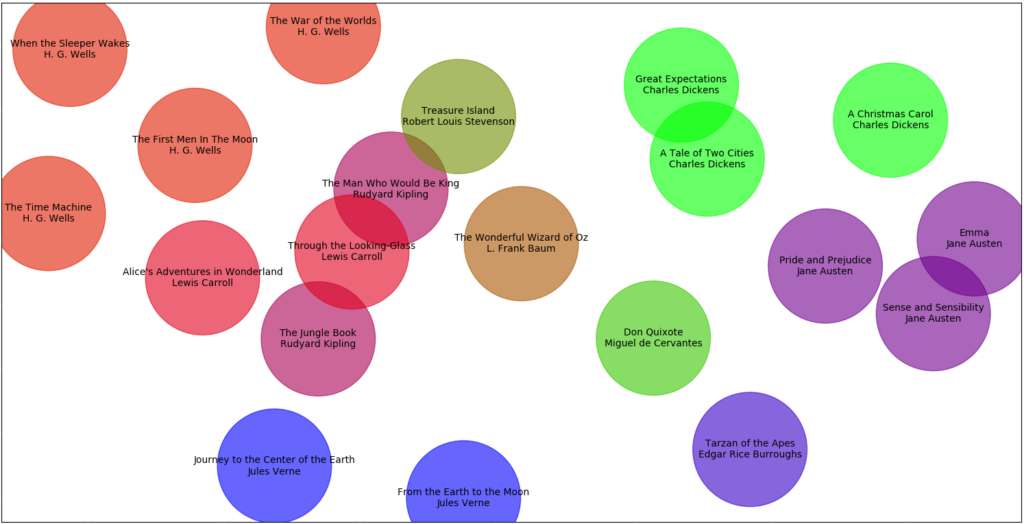
To create a picture like this, John had to reduce 128 dimensions down to just 2, in order to render it in a visual format 'humans' can understand. For a Discover AI project, we use all 128 dimensions to measure similarity...
I think this is fascinating. But before we can even begin to look at the results, we have to understand how we got here. In order to do the analysis, John removed all words which were considered ‘generic’ – in fact, those which “contributed little to the essence of the story” in order to make sure the machine could differentiate between the texts. This is a bold statement. What constitutes the ‘essence of a story’? This question isn’t a million miles away from how we define our sourcing areas at the start of a project – just as we ask which websites and brands can get to the heart of a category, so here it is which sentences and sentence structures are crucial to the story?
Of course, this in itself is just one analysis, that of the similarity of story. If we wanted to analyse how similar these novels were by structure, would we deem different words essential? Or if we wanted to understand how they used point of view – would the only thing that would be essential in that case be pronouns?
But in this instance, we’re focusing on story. In this light, the results which have emerged have some obvious causes, and raise some interesting questions. It makes sense that the Dickens is bunched together – but why are Great Expectations and A Tale of Two Cities more alike than A Christmas Carol? It is interesting that despite the ghost based narrative, A Christmas Carol is much closer to Jane Austen than the more fantastic H.G. Wells. Does this suggest it is more a romance than a fantasy? It is also potentially surprising that Jules Verne and H.G. Wells, both the founders of modern science fiction, in their way, are so far apart. Wells was purposefully choosing to move away from the Romantic Science Fiction of Verne, and perhaps this stylistic shift is reflected in their distance.
I could go on, but I shouldn’t. If you’re interested to learn more about ways data have been used for literary criticism in the past, this review of Franco Moretti’s only partially successful attempt is a good starting point.
However I think what this exercise demonstrates is that using AI in this way can be a really challenging exercise in how we define the terms of our questions, and an opportunity to challenge our own thinking. The results it then throws up can push that thinking in new directions – whether that be for analysing literature, or for a particular brand challenge.
If you want to learn more about how AI can help us be more human by challenging our thinking then contact us.
